
超快排软件怎么样-有没有人用过新发布的冰零快速队列,和胡电宝是同一个软
有没有人用过新发布的冰零快速队列,和胡电宝是同一个软件?它有效吗?
1、有没有人用过和护电宝一样的新软件冰零快排?它有效吗?
你可以自己挂机获取积分,在网页版中添加任务,只挂程序。
附加功能:
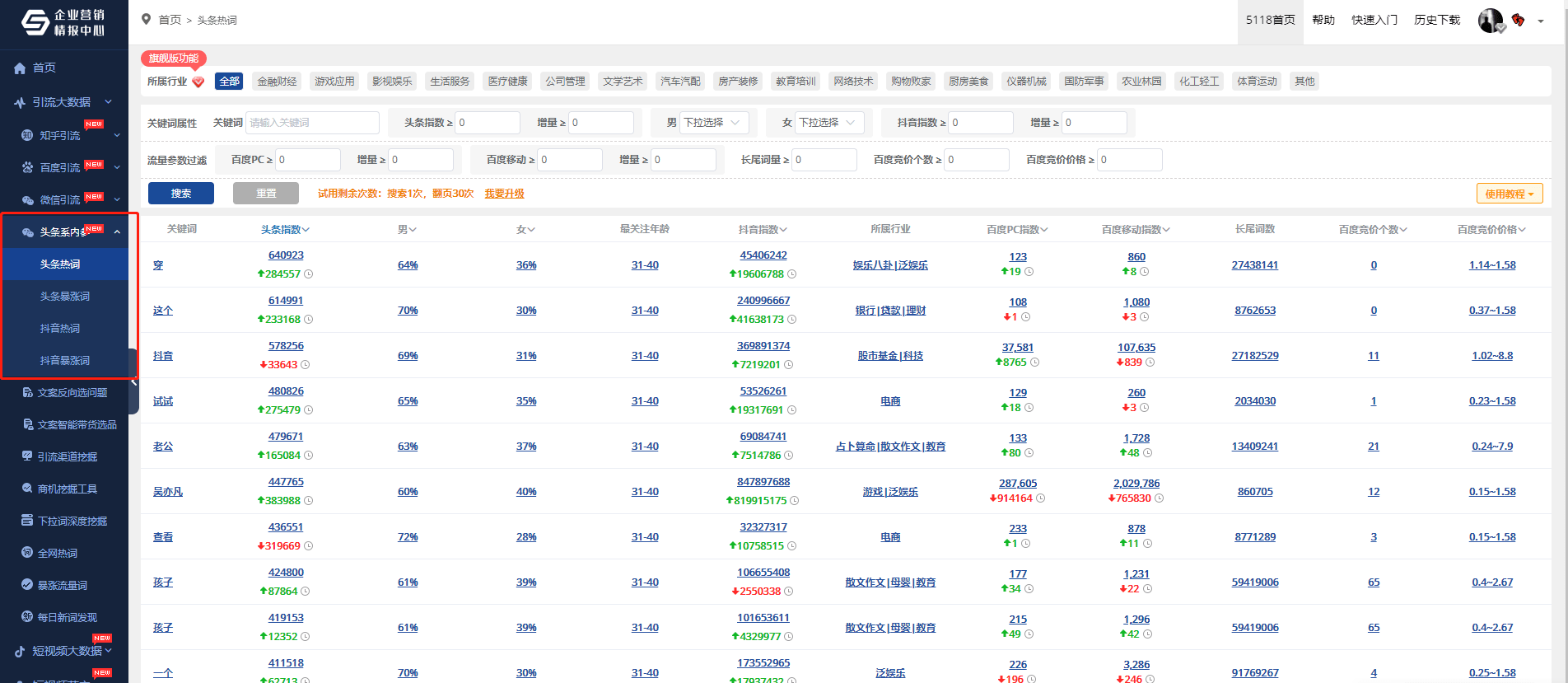
1、增加了前 10 页的点击次数。
2、添加了随机点击。在点击目标页面之前,随机点击其他网站,更符合模拟用户点击。
3、 10个空点击任务自动下线不浪费用户积分

2、类似互点宝的哪个软件效果最好
现在市面上有冰零点击和互点SEO,超快划船,人脉都不错。火电宝几年前就消失了。从2014年开始,我一直在使用火电宝软件。应该是第一批用户。效果非常好。它已被关闭,永恒的经典。现在我用的是SEO,效果还不错。 SEO平台已经使用了一年多。 hudianseo希望对你有所帮助
3、桶排序源码
io.open();//打开控制台
/**----------- ----------------- ----------------*桶排序**-- ------------------------------ -------------------- ----------------*/ 桶排序假设输入元素均匀且独立地分布在区间 [0,1) 内,即 0<=xandx<1;将区间划分为n个相同大小的子区间(桶),然后将n个输入按照大小分配到每个桶中,并对每个桶的内部进行排序。最后合并所有桶的排序结果。//插入排序算法
insert_sort=function(array){
for(right=2;#array){
vartop=array[right];
//将array[right]插入已排序的se[1、...right-1]
varleft=right-1;
while(leftandarray[left]>top){
array[left+1]= array[left];
left--;array[left+1]=top;returnarray;//bucket排序算法
bucket_sort=function(array){
varn=#array;
varbucket ={}
for(i=0;n;1){
bucket[i]={}//创建bucket varbucket_index
for(i=1;n;1){
bucket_index=math.floor(n*array[i]);
table.push(bucket[bucket_index],array[i]);//放入bucket for(i=1;n;1){
insert_sort(bucket[i]);//为每个桶插入排序 returntable.concat(table.unpack(bucket))io.print(--------------- -)
io.print(桶排序)
io.print(----------------)
array={};
//桶排序假设输入是由随机过程生成的小数。
math.randomize()
for(i=1;20;1){
table.push(array,math.random())/ /所以rt
array=bucket_sort(array)
//输出结果
for(i=1;#array;1){
io.print(array[i])execute(pause)//按任意键继续超快排软件怎么样}
io.close();//关闭控制台一年的高考考生人数为一万。 .
分析:对数据进行排序,如果基于比较进行高级排序,则平均比较次数为O(*)≈1亿。但是我们发现这些数据有特殊的条件:=
方法:创建 (-) 存储桶。将每个候选人的分数放入 f(score)=score- 的桶中。这个过程只需要从头到尾遍历数据。然后根据桶号的大小,依次输出桶中的值,即可以得到一个有序的序列。而且用***人和***人用积分很容易获得积分。
实际上,桶排序对数据条件有特殊要求。如果上面的分数不是从-,而是从0-2亿,那么分配2亿桶显然是不可能的。因此,桶排序有其局限性,适用于元素值集合不大的情况。文件中有一个整数,乱序排列,求中位数。内存限制为2G。把思路写出来就行了(内存限制为2G,就是说你可以用2G的空间来运行程序,不管本机其他软件的内存使用情况。) 关于中位数:数据排序后,数值在中间。即数据分为两部分,一部分大于值,另一部分小于值。中位数的位置:当样本数为奇数时,中位数=(N+1)/2;当样本数为偶数时,中位数为N/2和1+N/2的均值(则数的中位数为5G最大数和5G+1最大数的均值)。
分析:既然要求中位数,想排序就很简单了。那么基于字节的桶排序是一种可行的方法。
思路:以整数的每1个字节为关键字,也就是说一个整数可以分为4个key,最高阶的key越大,整数越大。如果高阶键相同,则比较下一个高阶键。整个比较过程类似于字符串的字典顺序。
第一步:每2G将整数读入内存,然后遍历这个,即(**)*2/4数据。每个数据使用位操作>>取出最高8位(31-24)。这8bits(0-)最多代表一个桶,那么可以根据8bits的值来确定要丢弃的桶数。最后将每个bucket写入一个磁盘文件,每个bucket中的数据个数统计在内存NUM[]中。
成本:(1)依次将数据读入内存的IO成本(这是无法避免的,CPU不能直接对磁盘进行操作)。 (2) 遍历内存中的数据,这是一个O(n)的线性时间复杂度。 (3) 将一个bucket写回磁盘文件空间的成本是额外的,即数据传输时间的两倍。
第二步:根据内存中的桶数NUM[],计算其中中位数的桶数。显然,2,,, 的中位数是 1,,, 数。假设加上前一个bucket的数据量,发现小于1、,,,加上第一个bucket的数据量,大于1、,,。注意,中位数必须在磁盘的第一个桶中。在这个桶的第一个,,,-N(0-) 位。 N(0-)表示前一个桶的数据量之和。然后将第一个文件中的整数读入内存。 (如果数据大致均匀分布,每个文件的大小估计在/=左右,当然不一定,但是超过2G的可能性很小)。注意在异常的情况下,需要读取的1号文件仍然大于2G,那么整个读取仍然可以按照第一步批量读取。
成本:(1)循环计算每个桶中数据的累积,需要O(M)的成本,其中m<. (2) 读入大约文件大小的IO成本。
第三步:继续对内存中某个bucket中整数的第二高8bit进行bucket排序(23-16)(它们的高8bit相同)。过程和第一步一样,也是一个bucket。
第四步:一直到最低字节(7-0bit)的桶排序结束。相信此时,在内存中使用快速排序就足够了。
整个过程的时间复杂度在O(n)的线性水平上(没有任何循环嵌套)。但主要时间花在了第一步的第二次内存-磁盘数据交换上,也就是将数据以单独的文件写回磁盘。一般来说,如果在第二步之后,如果内存可以容纳某个中值的文件,则可以直接排序(修改者注:我认为不写回磁盘继续桶排序会更高效)。高的?)。
有没有人用过新发布的冰零快速队列,和胡电宝是同一个软件?它有效吗?www.hdianbao.com



